Why SQL-Based Risk Monitoring Falls Short Against Modern Fraud
Why SQL-Based Risk Monitoring Falls Short Against Modern Fraud
Why SQL-Based Risk Monitoring Falls Short Against Modern Fraud
Today's fraud is real-time, networked, and AI-assisted. It moves across accounts, devices, and platforms faster than SQL queries can keep up. That's why.
Author
Team Bureau


See how Bureau has helped industry leaders defend against networked Industrial-scale frauds →
Schedule a Demo
TABLE OF CONTENTS
See Less
Most SQL-centric risk systems aren't constructed by design. They often evolve over time.
During the formative days of a fintech or digital bank, speed is more important than elegance. Data is needed almost at once. Transactional data is already present in the system. The analysts are also already conversant in SQL.
The start, therefore, requires a small number of thresholds, a little bit of joining, and a simple dashboard to identify "risky" behavior. The difficulty with these original decisions is that they tend to last. Initially designed as a workaround, these decisions inevitably morph into an infrastructure. Soon, instead of supporting fraud monitoring, SQL itself becomes the fraud system.
While SQL is not an issue, as many teams employ it at some stage in the process, the real danger is the data access layer being used as a decision engine risk.

Why SQL-driven fraud and AML systems don’t scale
What follows isn’t a theoretical critique of SQL. It’s a practical look at how SQL-based risk systems behave under real pressure: scenarios like higher volume, smarter fraud, and tighter regulatory scrutiny.
Each point shows a different failure mode, teams tend to hit as they scale.
SQL was never designed for real-time risk decisions
SQL answers questions like:
What happened yesterday?
How many transactions matched this pattern?
Fraud decisions need to answer:
Should this session continue right now?
Should this transaction be approved in the next 50 milliseconds?
That mismatch matters.
Related Read: From In-House Tools to Unified Fraud Intelligence
Fraud increasingly happens in-session, before data is fully written or aggregated.
By the time a SQL query runs, the window to intervene may already be closed.
From a fraud risk management (FRM) perspective, modern signals demand:
Sub-second decisions during login or checkout
Streaming evaluation, as events unfold
Stateful context across sessions and devices
Auditability suffers when logic lives in queries
Risk decisions must be traceable, explainable, and consistent over time. This isn’t a best practice or a maturity milestone. It’s a regulatory baseline. At some point, every growing fintech company is expected to explain not just what happened, but why a specific decision was made for a specific customer at a specific moment.
This is where SQL-centric approaches tend to break down. In many organizations, risk logic lives inside queries that are edited directly in production tools. Changes are made quickly to stop an active attack, documentation is sparse or limited to inline comments, and older logic is often overwritten, rather than preserved.
Over time, no one has a clear picture of how the system evolved. Six months later, even experienced team members struggle to explain why a particular transaction was blocked while another was allowed through.
From a regulatory standpoint, this is a problem. Examiners don’t care that a query existed or that it once made sense in context. They care about what logic was applied, when it was applied, and whether it was applied consistently across customers and time.
Related Read: Inside Bureau's AI-powered Orchestration Platform: Achieving a 360° View of Identity
Weighted risk is hard to model in flat queries
Fraud is largely probabilistic, and not binary in nature. Also, real risk is rarely a single red flag; instead it takes a cumulative strength of multiple weak signals.
To approximate scoring, teams add:
More joins
More CASE statements
More thresholds
But complexity doesn’t equal intelligence. It breaks down as shown below:
Signal Type | What SQL Struggles With |
Device reuse | Frequency vs severity tradeoffs |
Behavioral deviation | Baselines that shift over time |
Network exposure | Shared risk across entities |
SQL can’t express modern fraud signals well
SQL works on data represented in rows, whereas fraud detection works largely based on relationships formed out of data points.
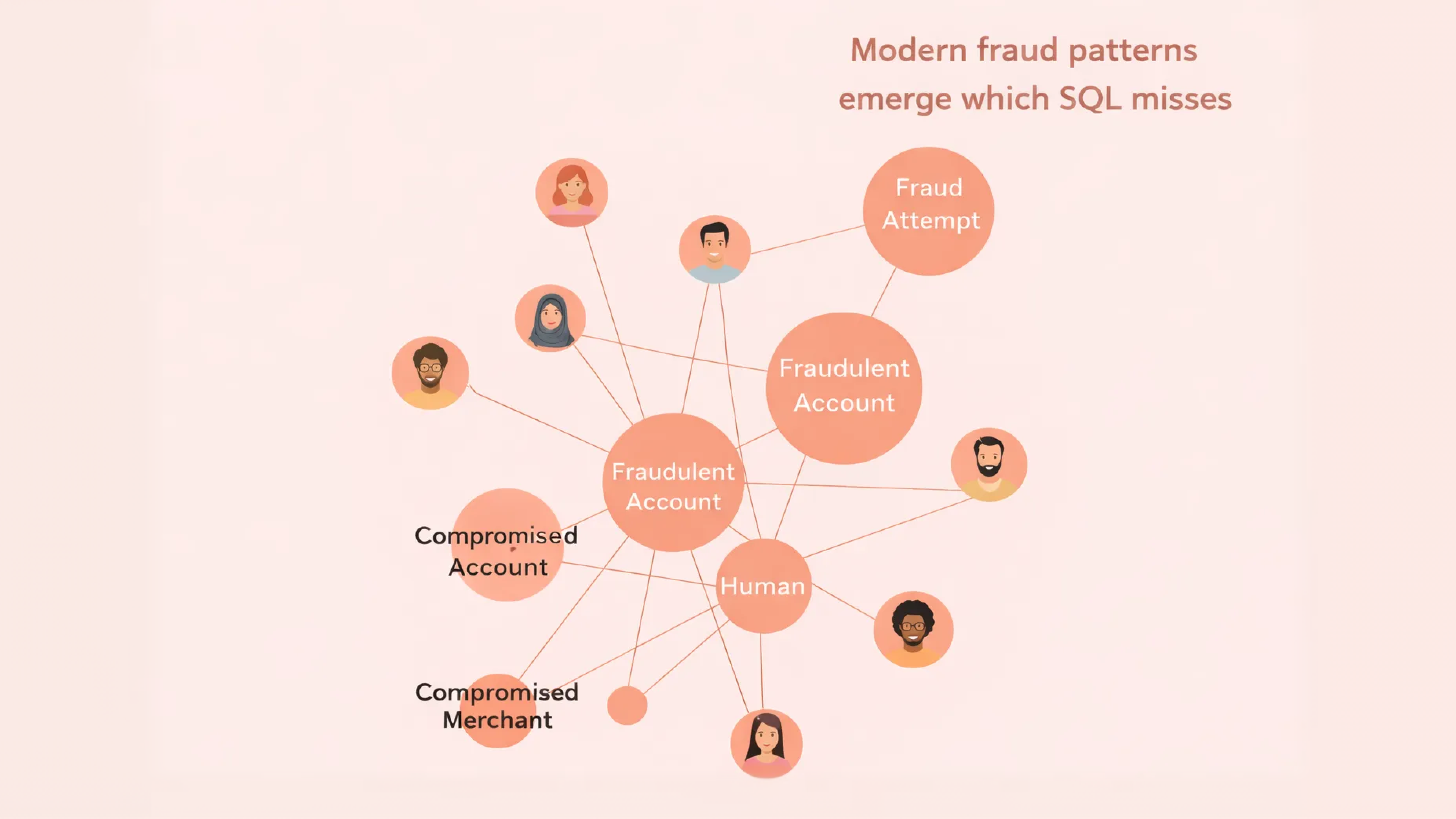
Modern fraud patterns emerge across:
Graphs of connected accounts
Sequences of events
Behavioral timelines that evolve
This is where SQL starts to feel less equipped. It can fetch the data, but struggles to express the insight without heavy logic layered on the top.
Performance degrades as rules grow
As fraud logic expands inside SQL, joins get deeper, queries grow heavier, and indexing turns into the game of whack-a-mole. Each new rule may seem harmless in isolation, but together they add real load to the system. Over time, risk checks start creeping into the critical path of transaction approvals, login flows, and payment processing, where latency matters most.

At that point, performance stops being a purely technical concern. It becomes a business problem. Slower decisions affect conversion rates, erode user trust, and ultimately hit revenue. Every additional millisecond, spent waiting on a SQL rule, is a tax on the product.
Fraud prevention shouldn’t compete with the core experience it’s meant to protect.
Compliance teams become dependent on engineers
Risk teams need autonomy to respond to threats as they emerge. SQL-centric systems tend to centralize control with engineering instead.
Operationally, this often means updating a rule requires engineering review, coordinated deployments, and careful testing to avoid breaking existing queries. What should be a fast response to a new fraud pattern, turns into a multi-step process with handoffs and delays.
Why engineering teams should push back on SQL-only risk systems
This isn’t about engineering saying “no” to risk or compliance. It’s about engineering recognizing when a system is being asked to do something it was never designed for, and when that choice will come back as an incident, an outage, or a painful postmortem.
SQL-only risk systems often survive because they work well enough early on. But engineering teams usually feel the cracks first: performance issues, brittle logic, and escalating operational overhead. That’s the moment to push back and not to block progress, but to redirect it.
Fraud prevention is not a CRUD problem
Most engineering systems built on SQL are optimized for CRUD operations: create, read, update, delete. They assume clear inputs, predictable access patterns, and relatively static logic.
Fraud prevention doesn’t behave that way.
Fraud decisions are:
Event-driven, not request-driven
Stateful, not transactional
Probabilistic, not deterministic
Trying to model fraud logic as a series of SQL queries turns a dynamic decision problem into a static data retrieval exercise.
From an engineering perspective, this is a mismatch in problem shape. SQL isn’t wrong. It’s just being asked to solve the wrong class of problem.
Engineering time is misallocated
One of the quieter costs of SQL-centric risk systems is the engineering time they consume over the long run.
Instead of building resilient decision services, scalable event pipelines, and clear interfaces between product and risk; engineering teams end up:
Optimizing queries
Adding indexes to keep rules alive
Debugging production joins during fraud spikes
This work is rarely planned and almost always reactive. It pulls senior engineers into maintenance mode and is taxing on the team and its time.
Risk logic belongs in purpose-built systems
Fraud logic isn’t just data access. It’s decision-making under uncertainty. That logic belongs in systems designed for exactly that.
Decision engines: Decision engines provide a clear, explicit place where risk logic lives. They make it possible to version rules, combine signals, and explain outcomes without burying logic inside queries.
Risk orchestration layers: An orchestration layer allows teams to control how signals are evaluated, weighted, and combined. It separates what signals exist from how decisions are made, which is critical as fraud patterns evolve.
Streaming systems: Streaming systems enable real-time evaluation as events occur. They support stateful context, low-latency decisions, and continuous assessment, all things which SQL struggles to express without heavy workarounds.
The real tradeoff engineering teams should call out
Building fraud logic in SQL solves today’s problem while creating tomorrow’s outage.
It reduces short-term friction, but it accumulates long-term risk:
Performance degrades quietly
Logic becomes brittle and opaque
Changes get riskier over time
Engineering teams are often the ones who inherit the consequences, especially during incidents, regulatory escalations, or sudden traffic spikes.
The goal isn’t to remove SQL from the stack. It’s to stop treating it as the brain of the fraud risk management system.
What modern risk management looks like in 2026
Up to this point, the focus has been on where SQL-centric systems fall short. The more useful question is what replaces them, given how fintechs actually operate today.
Modern risk monitoring isn’t about throwing out rules or abandoning databases. It’s about changing the mental model. Risk is no longer a static checklist evaluated at a single moment, but a living assessment that evolves as users, devices, and networks interact over time.
In 2026, the teams doing this effectively, will share a few common principles, as described below:
Event-driven, not batch-driven
In modern systems, risk decisions are triggered by events, not schedules. Every meaningful action, like login attempts, device changes, payment initiation, profile updates, produces a signal that can be evaluated immediately.
This shift matters because fraud doesn’t wait. Event-driven systems allow teams to:
Intervene mid-session
Adjust risk in real time
React as behavior unfolds, not after it’s stored

Batch processing still has a place for analysis and reporting. But, it just shouldn’t be the front line of defense.
Signal-based, not rule-heavy
Rules still exist, but they’re no longer the center of the system.
Modern risk platforms focus on collecting and interpreting signals, then combining them into a coherent view of risk. Instead of asking, “Did this transaction violate a rule?” the system asks, “What does the full set of signals tell us about intent and trust right now?”
This approach:
Reduces false positives
Makes it easier to tune risk without rewriting logic
Allows weak signals to add up meaningfully
Continuous, not one-time
Older systems tend to make a single decision and move on. Modern risk systems assume that trust is provisional.
A user who looks safe at login may behave differently during checkout.
A device that was trusted last week may start showing signs of automation today.
Risk needs to be reassessed continuously as new information arrives. Continuous monitoring is what allows teams to escalate (or de-escalate) risks dynamically, step up authentication when necessary, and avoid rash, one-time decisions that create false positives.
Related Read: Effective Transaction Monitoring: How To Shield Your Business from Devastating Financial Crimes
Explainable, not opaque
As systems grow more sophisticated, explainability becomes more relevant and necessary.
Modern risk monitoring systems are built to answer:
Which signals contributed to this decision?
How were they weighted?
What changed compared to a previous decision?
This information is not just to inform regulators but also to help internal teams debug issues, tune performance, and build confidence across fraud, compliance, and engineering.
Other signals that actually matter
Modern risk management systems don’t look for single red flags. They look for patterns that persist, connect, and evolve. The most useful signals share one trait: they gain meaning over time.
Here’s how leading teams think about them.
Instead of labeling devices as “trusted” or “untrusted,” modern systems ask a simpler question: ‘Is this device behaving consistently over time?’
A stable device:
| An unstable device:
|
Instability doesn’t prove fraud on its own. But it’s often the earliest signal that something is off and could snowball into a bigger risk.
Behavioral consistency: Does this look like the same user?
Behavioral signals answer a different question: Is the user acting like themselves?
In addition to control thresholds, they also look for other deviation like:
Changes in navigation flow
Sudden shifts in timing or velocity
Actions that don’t match historical patterns
This is especially powerful because it’s hard to fake consistently. Fraud tools can mimic attributes, but sustained behavioral imitation is much harder to maintain across sessions.
Related Read: Fraudulent Transactions: Behavioral Red Flags Commonly Ignored
Network exposure: Who and what is this connected to?
We have seen many times that fraud is rarely isolated. It is proven to move through a shared infrastructure.
Network exposure looks beyond the individual event and asks:
What else touches this device, IP, or identity?
How often do similar patterns repeat elsewhere?
Are there hidden clusters forming over time?
Connections that look harmless in isolation become risky when viewed as part of a broader network. It is here that SQL’s downside becomes evident. It lists rows, whereas network exposure explains the pattern.
Identity linkage over time: what story is this identity telling?
Identity isn’t a static record but the user’s history that is revealed over a period of time. Modern risk systems treat identity as something that accumulates context rather than being evaluated in a single moment.
This view is critical for catching low-noise fraud, activity that seems deliberately slow, subtle, and designed to stay under the thresholds.
Instead of asking, “Is this risky right now?” the system asks, “How has this risk evolved?”
How these signals work together
Individually, each signal is weak. That’s intentional.
The power comes from combination:
A slightly unstable device
A small behavioral deviation
A loose network connection
This is the shift modern risk teams are making: away from single-rule decisions and toward systems that interpret signals in context.
How Bureau enables risk beyond SQL rules
Bureau isn’t positioned as a replacement for an existing data stack. The databases, warehouses, and event stores remain exactly where they are. Bureau sits above them as a decision layer, focused on interpreting signals and producing consistent, real-time risk outcomes.
Bureau’s core capabilities in enabling risk beyond SQL rules include:
Real-time risk scoring: Bureau evaluates events as they happen, producing sub-second risk scores that can be used directly in login, checkout, and transaction flows. Read more.
Device intelligence: It builds a persistent understanding of device stability, reuse, and trust, rather than treating each session or fingerprint as an isolated data point. Read more.
Behavioral analytics: Bureau tracks behavioral patterns over time and surfaces meaningful deviations, helping teams detect subtle shifts that static rules tend to miss. Read more.
Network and graph insights: By analyzing connections across devices, accounts, and infrastructure, Bureau exposes shared risk that row-based analysis can’t reveal. Read more.
Explainable decisions: Every decision is accompanied by clear reasoning, showing which signals mattered and how they influenced the outcome. Read more.
Audit-ready workflows: Risk logic, changes, and outcomes are versioned and traceable, making it easier to answer regulatory questions without reconstructing intent after the fact. Read more.
Together, these capabilities allow teams to move beyond SQL-bound rules and toward a system that reasons about risk the way fraud actually behaves: continuously, contextually, and with accountability built in.
Upgrade fraud risk management today.See how Bureau delivers real-time, explainable fraud intelligence beyond SQL rules. |
Most SQL-centric risk systems aren't constructed by design. They often evolve over time.
During the formative days of a fintech or digital bank, speed is more important than elegance. Data is needed almost at once. Transactional data is already present in the system. The analysts are also already conversant in SQL.
The start, therefore, requires a small number of thresholds, a little bit of joining, and a simple dashboard to identify "risky" behavior. The difficulty with these original decisions is that they tend to last. Initially designed as a workaround, these decisions inevitably morph into an infrastructure. Soon, instead of supporting fraud monitoring, SQL itself becomes the fraud system.
While SQL is not an issue, as many teams employ it at some stage in the process, the real danger is the data access layer being used as a decision engine risk.
Why SQL-driven fraud and AML systems don’t scale
What follows isn’t a theoretical critique of SQL. It’s a practical look at how SQL-based risk systems behave under real pressure: scenarios like higher volume, smarter fraud, and tighter regulatory scrutiny.
Each point shows a different failure mode, teams tend to hit as they scale.
SQL was never designed for real-time risk decisions
SQL answers questions like:
What happened yesterday?
How many transactions matched this pattern?
Fraud decisions need to answer:
Should this session continue right now?
Should this transaction be approved in the next 50 milliseconds?
That mismatch matters.
Related Read: From In-House Tools to Unified Fraud Intelligence
Fraud increasingly happens in-session, before data is fully written or aggregated.
By the time a SQL query runs, the window to intervene may already be closed.
From a fraud risk management (FRM) perspective, modern signals demand:
Sub-second decisions during login or checkout
Streaming evaluation, as events unfold
Stateful context across sessions and devices
Auditability suffers when logic lives in queries
Risk decisions must be traceable, explainable, and consistent over time. This isn’t a best practice or a maturity milestone. It’s a regulatory baseline. At some point, every growing fintech company is expected to explain not just what happened, but why a specific decision was made for a specific customer at a specific moment.
This is where SQL-centric approaches tend to break down. In many organizations, risk logic lives inside queries that are edited directly in production tools. Changes are made quickly to stop an active attack, documentation is sparse or limited to inline comments, and older logic is often overwritten, rather than preserved.
Over time, no one has a clear picture of how the system evolved. Six months later, even experienced team members struggle to explain why a particular transaction was blocked while another was allowed through.
From a regulatory standpoint, this is a problem. Examiners don’t care that a query existed or that it once made sense in context. They care about what logic was applied, when it was applied, and whether it was applied consistently across customers and time.
Related Read: Inside Bureau's AI-powered Orchestration Platform: Achieving a 360° View of Identity
Weighted risk is hard to model in flat queries
Fraud is largely probabilistic, and not binary in nature. Also, real risk is rarely a single red flag; instead it takes a cumulative strength of multiple weak signals.
To approximate scoring, teams add:
More joins
More CASE statements
More thresholds
But complexity doesn’t equal intelligence. It breaks down as shown below:
Signal Type | What SQL Struggles With |
Device reuse | Frequency vs severity tradeoffs |
Behavioral deviation | Baselines that shift over time |
Network exposure | Shared risk across entities |
SQL can’t express modern fraud signals well
SQL works on data represented in rows, whereas fraud detection works largely based on relationships formed out of data points.
Modern fraud patterns emerge across:
Graphs of connected accounts
Sequences of events
Behavioral timelines that evolve
This is where SQL starts to feel less equipped. It can fetch the data, but struggles to express the insight without heavy logic layered on the top.
Performance degrades as rules grow
As fraud logic expands inside SQL, joins get deeper, queries grow heavier, and indexing turns into the game of whack-a-mole. Each new rule may seem harmless in isolation, but together they add real load to the system. Over time, risk checks start creeping into the critical path of transaction approvals, login flows, and payment processing, where latency matters most.
At that point, performance stops being a purely technical concern. It becomes a business problem. Slower decisions affect conversion rates, erode user trust, and ultimately hit revenue. Every additional millisecond, spent waiting on a SQL rule, is a tax on the product.
Fraud prevention shouldn’t compete with the core experience it’s meant to protect.
Compliance teams become dependent on engineers
Risk teams need autonomy to respond to threats as they emerge. SQL-centric systems tend to centralize control with engineering instead.
Operationally, this often means updating a rule requires engineering review, coordinated deployments, and careful testing to avoid breaking existing queries. What should be a fast response to a new fraud pattern, turns into a multi-step process with handoffs and delays.
Why engineering teams should push back on SQL-only risk systems
This isn’t about engineering saying “no” to risk or compliance. It’s about engineering recognizing when a system is being asked to do something it was never designed for, and when that choice will come back as an incident, an outage, or a painful postmortem.
SQL-only risk systems often survive because they work well enough early on. But engineering teams usually feel the cracks first: performance issues, brittle logic, and escalating operational overhead. That’s the moment to push back and not to block progress, but to redirect it.
Fraud prevention is not a CRUD problem
Most engineering systems built on SQL are optimized for CRUD operations: create, read, update, delete. They assume clear inputs, predictable access patterns, and relatively static logic.
Fraud prevention doesn’t behave that way.
Fraud decisions are:
Event-driven, not request-driven
Stateful, not transactional
Probabilistic, not deterministic
Trying to model fraud logic as a series of SQL queries turns a dynamic decision problem into a static data retrieval exercise.
From an engineering perspective, this is a mismatch in problem shape. SQL isn’t wrong. It’s just being asked to solve the wrong class of problem.
Engineering time is misallocated
One of the quieter costs of SQL-centric risk systems is the engineering time they consume over the long run.
Instead of building resilient decision services, scalable event pipelines, and clear interfaces between product and risk; engineering teams end up:
Optimizing queries
Adding indexes to keep rules alive
Debugging production joins during fraud spikes
This work is rarely planned and almost always reactive. It pulls senior engineers into maintenance mode and is taxing on the team and its time.
Risk logic belongs in purpose-built systems
Fraud logic isn’t just data access. It’s decision-making under uncertainty. That logic belongs in systems designed for exactly that.
Decision engines: Decision engines provide a clear, explicit place where risk logic lives. They make it possible to version rules, combine signals, and explain outcomes without burying logic inside queries.
Risk orchestration layers: An orchestration layer allows teams to control how signals are evaluated, weighted, and combined. It separates what signals exist from how decisions are made, which is critical as fraud patterns evolve.
Streaming systems: Streaming systems enable real-time evaluation as events occur. They support stateful context, low-latency decisions, and continuous assessment, all things which SQL struggles to express without heavy workarounds.
The real tradeoff engineering teams should call out
Building fraud logic in SQL solves today’s problem while creating tomorrow’s outage.
It reduces short-term friction, but it accumulates long-term risk:
Performance degrades quietly
Logic becomes brittle and opaque
Changes get riskier over time
Engineering teams are often the ones who inherit the consequences, especially during incidents, regulatory escalations, or sudden traffic spikes.
The goal isn’t to remove SQL from the stack. It’s to stop treating it as the brain of the fraud risk management system.
What modern risk management looks like in 2026
Up to this point, the focus has been on where SQL-centric systems fall short. The more useful question is what replaces them, given how fintechs actually operate today.
Modern risk monitoring isn’t about throwing out rules or abandoning databases. It’s about changing the mental model. Risk is no longer a static checklist evaluated at a single moment, but a living assessment that evolves as users, devices, and networks interact over time.
In 2026, the teams doing this effectively, will share a few common principles, as described below:
Event-driven, not batch-driven
In modern systems, risk decisions are triggered by events, not schedules. Every meaningful action, like login attempts, device changes, payment initiation, profile updates, produces a signal that can be evaluated immediately.
This shift matters because fraud doesn’t wait. Event-driven systems allow teams to:
Intervene mid-session
Adjust risk in real time
React as behavior unfolds, not after it’s stored
Batch processing still has a place for analysis and reporting. But, it just shouldn’t be the front line of defense.
Signal-based, not rule-heavy
Rules still exist, but they’re no longer the center of the system.
Modern risk platforms focus on collecting and interpreting signals, then combining them into a coherent view of risk. Instead of asking, “Did this transaction violate a rule?” the system asks, “What does the full set of signals tell us about intent and trust right now?”
This approach:
Reduces false positives
Makes it easier to tune risk without rewriting logic
Allows weak signals to add up meaningfully
Continuous, not one-time
Older systems tend to make a single decision and move on. Modern risk systems assume that trust is provisional.
A user who looks safe at login may behave differently during checkout.
A device that was trusted last week may start showing signs of automation today.
Risk needs to be reassessed continuously as new information arrives. Continuous monitoring is what allows teams to escalate (or de-escalate) risks dynamically, step up authentication when necessary, and avoid rash, one-time decisions that create false positives.
Related Read: Effective Transaction Monitoring: How To Shield Your Business from Devastating Financial Crimes
Explainable, not opaque
As systems grow more sophisticated, explainability becomes more relevant and necessary.
Modern risk monitoring systems are built to answer:
Which signals contributed to this decision?
How were they weighted?
What changed compared to a previous decision?
This information is not just to inform regulators but also to help internal teams debug issues, tune performance, and build confidence across fraud, compliance, and engineering.
Other signals that actually matter
Modern risk management systems don’t look for single red flags. They look for patterns that persist, connect, and evolve. The most useful signals share one trait: they gain meaning over time.
Here’s how leading teams think about them.
Instead of labeling devices as “trusted” or “untrusted,” modern systems ask a simpler question: ‘Is this device behaving consistently over time?’
A stable device:
| An unstable device:
|
Instability doesn’t prove fraud on its own. But it’s often the earliest signal that something is off and could snowball into a bigger risk.
Behavioral consistency: Does this look like the same user?
Behavioral signals answer a different question: Is the user acting like themselves?
In addition to control thresholds, they also look for other deviation like:
Changes in navigation flow
Sudden shifts in timing or velocity
Actions that don’t match historical patterns
This is especially powerful because it’s hard to fake consistently. Fraud tools can mimic attributes, but sustained behavioral imitation is much harder to maintain across sessions.
Related Read: Fraudulent Transactions: Behavioral Red Flags Commonly Ignored
Network exposure: Who and what is this connected to?
We have seen many times that fraud is rarely isolated. It is proven to move through a shared infrastructure.
Network exposure looks beyond the individual event and asks:
What else touches this device, IP, or identity?
How often do similar patterns repeat elsewhere?
Are there hidden clusters forming over time?
Connections that look harmless in isolation become risky when viewed as part of a broader network. It is here that SQL’s downside becomes evident. It lists rows, whereas network exposure explains the pattern.
Identity linkage over time: what story is this identity telling?
Identity isn’t a static record but the user’s history that is revealed over a period of time. Modern risk systems treat identity as something that accumulates context rather than being evaluated in a single moment.
This view is critical for catching low-noise fraud, activity that seems deliberately slow, subtle, and designed to stay under the thresholds.
Instead of asking, “Is this risky right now?” the system asks, “How has this risk evolved?”
How these signals work together
Individually, each signal is weak. That’s intentional.
The power comes from combination:
A slightly unstable device
A small behavioral deviation
A loose network connection
This is the shift modern risk teams are making: away from single-rule decisions and toward systems that interpret signals in context.
How Bureau enables risk beyond SQL rules
Bureau isn’t positioned as a replacement for an existing data stack. The databases, warehouses, and event stores remain exactly where they are. Bureau sits above them as a decision layer, focused on interpreting signals and producing consistent, real-time risk outcomes.
Bureau’s core capabilities in enabling risk beyond SQL rules include:
Real-time risk scoring: Bureau evaluates events as they happen, producing sub-second risk scores that can be used directly in login, checkout, and transaction flows. Read more.
Device intelligence: It builds a persistent understanding of device stability, reuse, and trust, rather than treating each session or fingerprint as an isolated data point. Read more.
Behavioral analytics: Bureau tracks behavioral patterns over time and surfaces meaningful deviations, helping teams detect subtle shifts that static rules tend to miss. Read more.
Network and graph insights: By analyzing connections across devices, accounts, and infrastructure, Bureau exposes shared risk that row-based analysis can’t reveal. Read more.
Explainable decisions: Every decision is accompanied by clear reasoning, showing which signals mattered and how they influenced the outcome. Read more.
Audit-ready workflows: Risk logic, changes, and outcomes are versioned and traceable, making it easier to answer regulatory questions without reconstructing intent after the fact. Read more.
Together, these capabilities allow teams to move beyond SQL-bound rules and toward a system that reasons about risk the way fraud actually behaves: continuously, contextually, and with accountability built in.
Upgrade fraud risk management today.See how Bureau delivers real-time, explainable fraud intelligence beyond SQL rules. |
TABLE OF CONTENTS
See More
Recommended Blogs



Landing Page.
Simple, bold.
Sign Up
Download

Products
Solutions
Resources


© 2026 Bureau . All rights reserved.
Solutions
Industries
Resources
Company
Solutions
Industries
Resources
Company
© 2026 Bureau . All rights reserved.
Follow Us
Leave behind fragmented tools. Stop fraud rings, cut false declines, and deliver secure digital journeys at scale
Our Presence








Leave behind fragmented tools. Stop fraud rings, cut false declines, and deliver secure digital journeys at scale
Our Presence
© 2026 Bureau . All rights reserved.