Predictive Trust: The New Standard for Fraud Risk Management
Predictive Trust: The New Standard for Fraud Risk Management
Predictive Trust: The New Standard for Fraud Risk Management
At scale, fraud moves faster than investigations. Discover how predictive trust helps businesses prevent fraud before losses occur.
Author
Prasanna Venkat


See how Bureau has helped industry leaders defend against networked Industrial-scale frauds →
Schedule a Demo
TABLE OF CONTENTS
See Less
As a front-line fraud prevention organization, Bureau has noticed analysts spending their entire workdays analyzing patterns to look for trust scores. These patterns could be anything from 20 swipes an hour to a jailbroken phone, or even how fast someone types.
On similar lines, not so long ago, containing a blast radius was the foundation of cyber-security. Teams would find a middle ground, fence it off, and fix it later. Today, however, teams fighting fraud, chase the trust score, approving good users while rejecting the bad ones. The common ground: after-the-fact signals are used by both.
This, however, is not foresight, but forensics.

Having assisted global clients fight fraud at scale, it is clear that by the time an investigation ticket opens, mule networks have already laundered funds and spun up fresh devices. The question, therefore, is how do businesses ensure effective fraud risk management.
The answer lies in a radical new approach: Predictive Trust.
What is predictive trust
Predictive trust is not just another rules engine wrapped in an AI bandwagon. It’s a living graph.
Here every login, device ping, location hop, and KYC attribute updates the probability that an identity is who it claims to be. And all the steps happen in seconds, not minutes:
Signal Saturation: Looking for "Device DNA", the hardware attributes that offer 99.7% persistence even after a factory reset. Even if a device has been "cleaned," the DNA should still tell the truth.
Graph Neural Networks (GNNs): Humans can’t see patterns across billions of data points, but GNNs can. They identify "shared edges" and fraud clusters that would otherwise stay hidden in the noise.
Continuous Feedback Loops: The risk scores shouldn't be set in stone. They need to learn from every blocked mule and every power-user approval, retraining the model every 24 hours to stay ahead of the curve.
This multi-layered stack turns static “scores” into streaming trust curves that rise or fall with each fresh breadcrumb.
Related Read: 5 Key Features of a Powerful Device ID
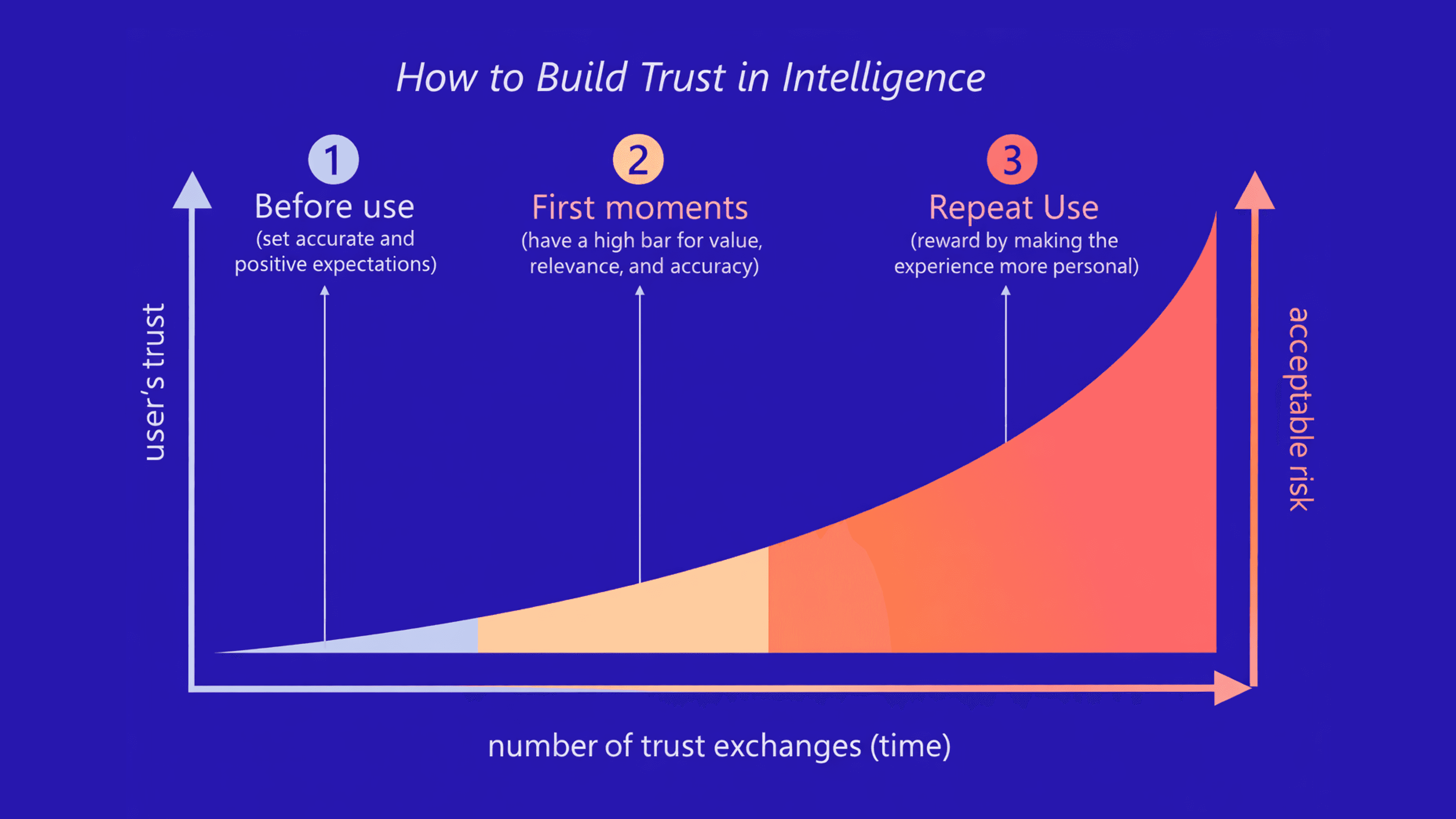
How a predictive trust engine operates
A predictive trust engine continuously analyzes signals across identity, device, behavior, and network patterns to anticipate risk before fraud occurs. It scores trust in real time and adapts with each interaction, powering confident approvals while proactively stopping high-risk activity. Typical steps include:
Data Input: Aggregates signals from device IDs, behavioral biometrics, telco metadata, IP reputation, and system logs.
Risk Analysis: A GNN processes these signals to score identities against known fraud clusters in real-time.
Automated Response: Triggers adaptive MFA, step-up KYC, or immediate blocks through automated logic, reducing the need for manual intervention.
Feedback Loop: Outcomes, including refunds, chargebacks, and manual reviews are fed back into the system to retrain the model every 24 hours. Think of it as live traffic navigation for user identity. The result: The system identifies "congestion" (fraud) in real-time and reroutes legitimate users before they hit friction.
Why security and fraud teams must work closely
In a previous article, it was explained in detail why fraud teams must adopt frameworks like MITRE ATT&CK and D3FEND that are commonly used in fighting cybersecurity issues. Here is a comparison for the reactive legacy mindset vs proactive trust mindset:
The Legacy Mindset | The Predictive-Trust Mindset |
Patch after the breach: Fix the hole once the money is gone. | Real-time downgrades: Lower trust scores the moment a signal drifts. |
Siloed budgets: Fraud vs. Security as separate line items. | Converged risk: One unified stack for all identity decisions. |
Annual audits: Checking the boxes once a year. | Streaming telemetry: Continuous control via real-time data. |
One converged signal stack routinely cuts both fraud losses and false-positive churn. Early adopters of Bureau’s upgraded DeviceID saw up-to a whopping 78% fraud reduction within a month, without hammering UX.
Related Read: Synthetic Identities Are the New Advanced Persistent Threats
The 90-day roadmap to predictive trust
To stop triaging and start predicting, here is how security teams should spend their next quarter:
Days 1–30 (The Audit): Map every signal that touches onboarding and payments. Where are the gaps? Which signals are siloed?
Days 31–60 (The Infrastructure): Stand up a low-latency event bus. Ensure DeviceID and location intelligence stream into a unified feature store, instead of sitting in a database.
Days 61–90 (The Switch): Move away from "All or Nothing" gating. Implement risk-tiered flows where low scores pass, mid-range scores trigger adaptive MFA, and high-risk signals get a hard block.
By quarter’s end, the reason why every block or approval happened should become clear, with fewer chargebacks, and an explainable audit trail for regulators.
The details that matter
Graph intelligence is the secret weapon
Synthetic IDs are particularly nasty because they age like fine wine. By the time they "bust out," they look like loyal customers that have existed for years. They also pass all the velocity checks.
But here's where the graph model saves the day. Fraudsters can fake names, social security numbers, even social media histories. What they can't fake perfectly is the physical infrastructure. The graph spots clusters of supposedly separate identities that share a MAC address, an identical browser fingerprint, or the same pattern of dormant behavior. Even with 10,000 "clean" identities, these shared connections give them away.
Beating bot-as-a-service
Bot fraud has become highly sophisticated. They are no longer simple bots; these advanced things mimic mouse movements, type at human speeds, even simulate distraction. They're trying to look exactly like real users.
The solution, therefore, lies in entropy. Every device has a unique fingerprint, browser plugins, screen resolution, battery status, clock skew. Even if a bot perfectly mimics human behavior, when 500 supposedly different users all have the exact same battery level, OS version, and rendering fingerprint, the math doesn't work. The statistical probability of that coincidence is basically zero, and that's the biggest red flag.
Protecting against adversarial AI
This is the newest challenge. If a risk model uses an LLM to flag suspicious activity, someone could theoretically slip malicious prompts into transaction notes or user profiles to trick the model into calling something "low risk" when it's not.
The defense is constant vigilance. Monitor not just whether the model is getting things right, but why it thinks it's right. If the model suddenly starts ignoring key risk signals like rapid IP switching, that's adversarial drift and it needs to be caught fast.
Five questions for the next planning meeting
Can trust be calculated in milliseconds without forcing real users through endless captchas?
Are the fraud and security teams looking at the same data, or are they operating in separate silos?
How long do mule networks operate in the system before being caught?
Which critical signals: device, telco, location,are still stuck in separate systems?
What went wrong when users who were blocked turned out to be legitimate?
If these questions go unanswered, the business is still playing defense.
Final thoughts: Build trust just like patching vulnerabilities
When a zero-day vulnerability hits, cybersecurity teams have to patch immediately, even before they fully understand what happened. Fraud leaders now face the same urgency. Either build predictive trust or stay stuck in perpetual crisis mode.
Bureau’s contextual engine isn’t magic; it’s simply the first credible bridge between “blast radius” and “trust score.” Businesses that spend this year laying that bridge, will be compounding customer loyalty next year instead of counting losses. Learn more, talk to an expert now.
As a front-line fraud prevention organization, Bureau has noticed analysts spending their entire workdays analyzing patterns to look for trust scores. These patterns could be anything from 20 swipes an hour to a jailbroken phone, or even how fast someone types.
On similar lines, not so long ago, containing a blast radius was the foundation of cyber-security. Teams would find a middle ground, fence it off, and fix it later. Today, however, teams fighting fraud, chase the trust score, approving good users while rejecting the bad ones. The common ground: after-the-fact signals are used by both.
This, however, is not foresight, but forensics.
Having assisted global clients fight fraud at scale, it is clear that by the time an investigation ticket opens, mule networks have already laundered funds and spun up fresh devices. The question, therefore, is how do businesses ensure effective fraud risk management.
The answer lies in a radical new approach: Predictive Trust.
What is predictive trust
Predictive trust is not just another rules engine wrapped in an AI bandwagon. It’s a living graph.
Here every login, device ping, location hop, and KYC attribute updates the probability that an identity is who it claims to be. And all the steps happen in seconds, not minutes:
Signal Saturation: Looking for "Device DNA", the hardware attributes that offer 99.7% persistence even after a factory reset. Even if a device has been "cleaned," the DNA should still tell the truth.
Graph Neural Networks (GNNs): Humans can’t see patterns across billions of data points, but GNNs can. They identify "shared edges" and fraud clusters that would otherwise stay hidden in the noise.
Continuous Feedback Loops: The risk scores shouldn't be set in stone. They need to learn from every blocked mule and every power-user approval, retraining the model every 24 hours to stay ahead of the curve.
This multi-layered stack turns static “scores” into streaming trust curves that rise or fall with each fresh breadcrumb.
Related Read: 5 Key Features of a Powerful Device ID
How a predictive trust engine operates
A predictive trust engine continuously analyzes signals across identity, device, behavior, and network patterns to anticipate risk before fraud occurs. It scores trust in real time and adapts with each interaction, powering confident approvals while proactively stopping high-risk activity. Typical steps include:
Data Input: Aggregates signals from device IDs, behavioral biometrics, telco metadata, IP reputation, and system logs.
Risk Analysis: A GNN processes these signals to score identities against known fraud clusters in real-time.
Automated Response: Triggers adaptive MFA, step-up KYC, or immediate blocks through automated logic, reducing the need for manual intervention.
Feedback Loop: Outcomes, including refunds, chargebacks, and manual reviews are fed back into the system to retrain the model every 24 hours. Think of it as live traffic navigation for user identity. The result: The system identifies "congestion" (fraud) in real-time and reroutes legitimate users before they hit friction.
Why security and fraud teams must work closely
In a previous article, it was explained in detail why fraud teams must adopt frameworks like MITRE ATT&CK and D3FEND that are commonly used in fighting cybersecurity issues. Here is a comparison for the reactive legacy mindset vs proactive trust mindset:
The Legacy Mindset | The Predictive-Trust Mindset |
Patch after the breach: Fix the hole once the money is gone. | Real-time downgrades: Lower trust scores the moment a signal drifts. |
Siloed budgets: Fraud vs. Security as separate line items. | Converged risk: One unified stack for all identity decisions. |
Annual audits: Checking the boxes once a year. | Streaming telemetry: Continuous control via real-time data. |
One converged signal stack routinely cuts both fraud losses and false-positive churn. Early adopters of Bureau’s upgraded DeviceID saw up-to a whopping 78% fraud reduction within a month, without hammering UX.
Related Read: Synthetic Identities Are the New Advanced Persistent Threats
The 90-day roadmap to predictive trust
To stop triaging and start predicting, here is how security teams should spend their next quarter:
Days 1–30 (The Audit): Map every signal that touches onboarding and payments. Where are the gaps? Which signals are siloed?
Days 31–60 (The Infrastructure): Stand up a low-latency event bus. Ensure DeviceID and location intelligence stream into a unified feature store, instead of sitting in a database.
Days 61–90 (The Switch): Move away from "All or Nothing" gating. Implement risk-tiered flows where low scores pass, mid-range scores trigger adaptive MFA, and high-risk signals get a hard block.
By quarter’s end, the reason why every block or approval happened should become clear, with fewer chargebacks, and an explainable audit trail for regulators.
The details that matter
Graph intelligence is the secret weapon
Synthetic IDs are particularly nasty because they age like fine wine. By the time they "bust out," they look like loyal customers that have existed for years. They also pass all the velocity checks.
But here's where the graph model saves the day. Fraudsters can fake names, social security numbers, even social media histories. What they can't fake perfectly is the physical infrastructure. The graph spots clusters of supposedly separate identities that share a MAC address, an identical browser fingerprint, or the same pattern of dormant behavior. Even with 10,000 "clean" identities, these shared connections give them away.
Beating bot-as-a-service
Bot fraud has become highly sophisticated. They are no longer simple bots; these advanced things mimic mouse movements, type at human speeds, even simulate distraction. They're trying to look exactly like real users.
The solution, therefore, lies in entropy. Every device has a unique fingerprint, browser plugins, screen resolution, battery status, clock skew. Even if a bot perfectly mimics human behavior, when 500 supposedly different users all have the exact same battery level, OS version, and rendering fingerprint, the math doesn't work. The statistical probability of that coincidence is basically zero, and that's the biggest red flag.
Protecting against adversarial AI
This is the newest challenge. If a risk model uses an LLM to flag suspicious activity, someone could theoretically slip malicious prompts into transaction notes or user profiles to trick the model into calling something "low risk" when it's not.
The defense is constant vigilance. Monitor not just whether the model is getting things right, but why it thinks it's right. If the model suddenly starts ignoring key risk signals like rapid IP switching, that's adversarial drift and it needs to be caught fast.
Five questions for the next planning meeting
Can trust be calculated in milliseconds without forcing real users through endless captchas?
Are the fraud and security teams looking at the same data, or are they operating in separate silos?
How long do mule networks operate in the system before being caught?
Which critical signals: device, telco, location,are still stuck in separate systems?
What went wrong when users who were blocked turned out to be legitimate?
If these questions go unanswered, the business is still playing defense.
Final thoughts: Build trust just like patching vulnerabilities
When a zero-day vulnerability hits, cybersecurity teams have to patch immediately, even before they fully understand what happened. Fraud leaders now face the same urgency. Either build predictive trust or stay stuck in perpetual crisis mode.
Bureau’s contextual engine isn’t magic; it’s simply the first credible bridge between “blast radius” and “trust score.” Businesses that spend this year laying that bridge, will be compounding customer loyalty next year instead of counting losses. Learn more, talk to an expert now.
TABLE OF CONTENTS
See More
Recommended Blogs



Landing Page.
Simple, bold.
Sign Up
Download

Products
Solutions
Resources


© 2026 Bureau . All rights reserved.
Solutions
Industries
Resources
Company
Solutions
Industries
Resources
Company
© 2026 Bureau . All rights reserved.
Follow Us
Leave behind fragmented tools. Stop fraud rings, cut false declines, and deliver secure digital journeys at scale
Our Presence








Leave behind fragmented tools. Stop fraud rings, cut false declines, and deliver secure digital journeys at scale
Our Presence
© 2026 Bureau . All rights reserved.